
TLDR:
- Hardware-software integration isn’t incidental; it can make or break your project. When hardware and software don’t evolve together, even small disconnects can derail timelines, budgets, and trust.
- Late-stage fixes cost exponentially more. A bug caught during design might cost dollars. The same bug in production? Think millions and lost market trust.
- Real failures happen at the seams. From rockets to robotics, integration breakdowns are rarely in the parts—they’re in the handoffs. That’s where risk lives.
- Co-design is leverage. Companies that align hardware and software from day one ship better products, faster and avoid becoming the next case study in what went wrong.
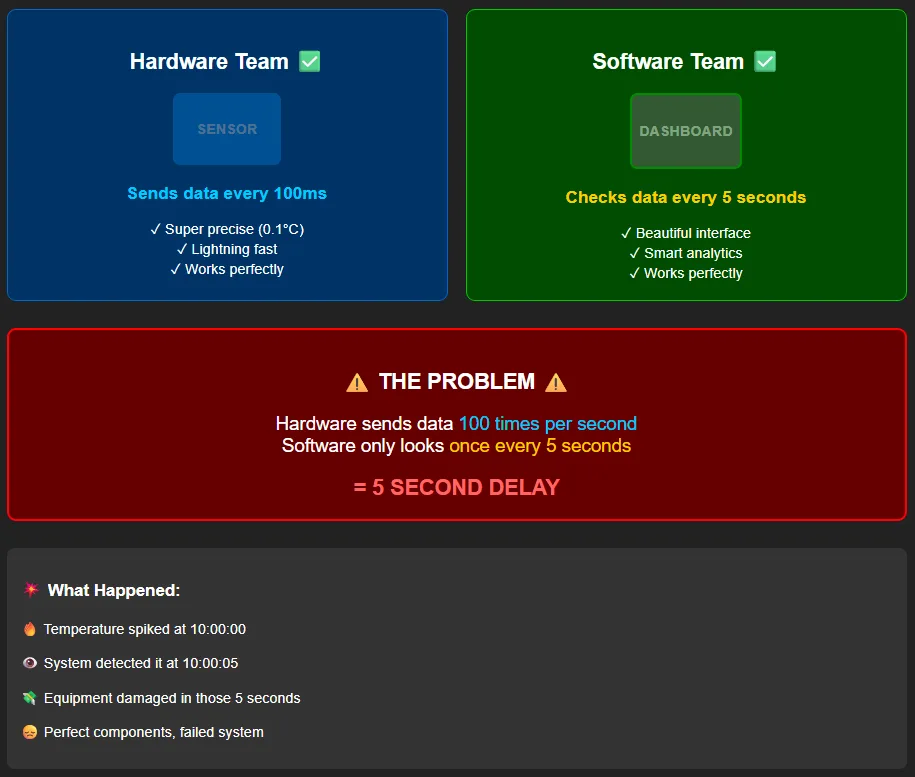
Your team just completed the most refined temperature monitoring solution you’ve ever built. The hardware engineers delivered a sensor with incredible precision—accurate to 0.1°C with sub-second response times. The software team built a beautiful real-time dashboard with predictive analytics and automated alerting. Both teams exceeded their individual specifications.
Then integration testing begins. The hardware team designed the sensor to output temperature readings every 100 milliseconds for maximum precision. The software team, focused on network efficiency and battery life, architected the system to poll for readings every 5 seconds. Nobody talked to each other about timing requirements.
The result? Your “real-time” monitoring system has a 5-second lag, your precision hardware is mostly idle, and your customer just discovered a critical temperature spike 5 seconds too late to prevent equipment damage. The hardware works perfectly. The software works perfectly. The integrated system fails catastrophically.
Welcome to the $2.4 trillion problem hiding in plain sight across every technology organization.
You’re Not Building Hardware or Software—You’re Building Systems
Here’s what every technical leader needs to understand: the era of discrete hardware and software products is over. As a former NASA Aerospace Safety Advisory Panel chair observed, “We are no longer building hardware into which we install a modicum of enabling software, we are actually building software systems which we wrap up in enabling hardware” (Fatal Software Failures in Spaceflight – MDPI).
This isn’t just philosophical; it’s a fundamental shift in how we must approach product architecture. Your “hardware” product likely contains millions of lines of firmware. Your “software” platform depends on precise timing relationships with sensors, actuators, and communication protocols. The value proposition lives entirely at the integration layer.
Hardware refers to the full range of physical components in a system, everything from processors and sensors to actuators, cameras, and connectivity modules. Software typically includes the user-facing applications and operating systems, while firmware plays a more behind-the-scenes role: it lives on the device itself, managing low-level operations and bridging the hardware to higher-level software layers.
The goal of integrating these elements is building a seamless, interdependent system. Take a fitness tracker, for example. On its own, a heart rate sensor or accelerometer doesn’t deliver value. It’s the firmware that manages sensor data, and the mobile app that interprets that data, delivering insights like step counts or sleep patterns. Together, the pieces create a coherent experience.
This kind of coordination isn’t limited to wearables. It powers systems across industries, from automated surgical lighting to fleet GPS systems to the millions of interconnected devices in the IoT. When integration is poorly handled, it’s not just a tech issue; it’s a product-level failure. It can stall launches, blow budgets, erode trust, or in mission-critical applications, cause real harm.
Economics of Getting Hardware-Software Integration Wrong
Let’s examine the financial reality. The Consortium for Information & Software Quality (CISQ) quantified the total cost of poor software quality in the U.S. at $2.41 trillion in 2022. To contextualize this figure: it represents approximately 10% of U.S. GDP flowing directly into technical debt and rework against a projected 2022 U.S. GDP of $23.35 trillion.
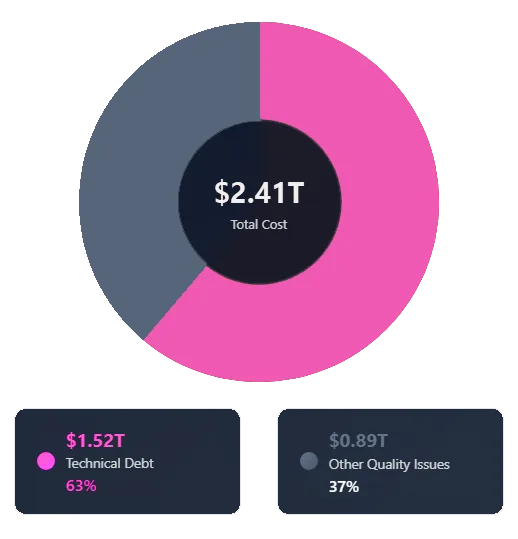
The most insidious component is accumulated technical debt, estimated at $1.52 trillion. Technical debt is the implied cost of rework caused by choosing an easy or limited solution now instead of using a better approach that would take longer. In integrated systems, this manifests as software patches compensating for hardware limitations that should have been addressed during architecture definition. Each workaround creates brittle dependencies that compound over time, making future updates exponentially more risky and expensive.
The Foundational NIST Findings
The fundamental understanding of this problem was established by a landmark 2002 study commissioned by the U.S. Department of Commerce’s National Institute of Standards and Technology (NIST), which found that software errors cost the U.S. economy an estimated $59.5 billion annually at the time.
More importantly, the NIST report identified the core dynamic that drives these costs: the timing of defect discovery. The study revealed that over half of all software errors were not found until “downstream” in the development process or during post-sale use by customers. The report concluded that an improved testing infrastructure could eliminate more than a third of these costs, which amounted to a potential savings of $22.2 billion at the time.
The Exponential Cost of Late-Stage Bug Fixes
The timing dynamics are brutal and follow what’s known as the “1-10-100 rule.” NIST’s foundational research established that production bug fixes cost up to 100 times more than design-phase corrections. This isn’t hyperbole. It reflects the cascading costs of emergency patches, customer support escalation, potential recalls, and reputational damage that accompanies post-launch integration failures.
The principle illustrates the exponential increase in cost based on development phase:
- Fixing a bug during the initial design and requirements phase represents a baseline cost (1x).
- If discovered during implementation or testing phase, costs multiply 6 to 15 times more than a design-phase fix.
- If the bug escapes into production, the cost can reach 100 times the original cost of fixing it in the design phase.
The Hidden Cost of Rework
Industry data shows that rework eats up 20–50% of project budgets on average, and in some cases, that number can spike to 200%. A telling comparison comes from construction, where studies reveal that up to 70% of rework stems from mistakes made early in design and engineering. The message is clear: the earlier you get alignment right, the less you pay for it later.
In the automotive industry, McKinsey estimates between 30-50% of the entire software development effort is dedicated solely to integration tasks . This represents massive capital allocation inefficiency. Your best engineers are spending cycles on non-value-added integration work instead of building competitive differentiation.
The Cascading Costs of Lost Opportunity and Reputation
While direct financial costs are staggering, the indirect consequences often inflict far greater long-term harm on organizations.
The High Cost of Delayed Time-to-Market
In today’s fast-paced technology markets, speed is a critical competitive weapon. Integration failures that push back launch dates hand first-mover advantage directly to rivals. For many products, a big portion of lifetime sales occurs within a narrow peak window. For example, missing the holiday shopping season may mean never recovering lost revenue.
For major electronics products with high sales volume expectations, a single day of delay can result in millions of dollars in lost sales opportunities when you consider not only revenue loss but also potential reduction in overall sales peak and lifetime volume as competitors fill the market vacuum.
The Erosion of Brand Reputation and Customer Trust
Hardware-software integration failures often manifest as buggy, unreliable, or unsafe products, destroying customer trust and inflicting lasting brand damage. Research shows that 32% of customers would stop doing business with a brand they loved after just one negative incident. Another report indicated that 90% of customers have actively chosen not to purchase from a company specifically because of its poor reputation.
Product recalls have a direct and measurable negative impact on stock prices, eroding shareholder value and making it more difficult and expensive to raise capital. In the age of social media, dissatisfied customers can instantly share negative experiences with a global audience, turning isolated technical glitches into widespread public relations crises.
The Internal Drain: Productivity and Morale
When products fail in the field, engineering teams are pulled off forward-looking projects into reactive “firefighting” mode. Some analyses suggest that 30-50% of development cycles can be consumed by fixing defects rather than building new features.
A culture of constant crisis and firefighting is toxic to employee morale, leading to burnout and higher employee turnover.
The Specter of Legal and Regulatory Consequences
In safety-critical systems like automotive, aerospace, and medical devices, integration failures can lead to injury or loss of life, inevitably resulting in costly lawsuits and substantial regulatory fines. High-profile failures can place companies under increased regulatory oversight, adding administrative burden, slowing future development, and increasing compliance costs for years.
When Integration Failures Become Industry Disasters
The Ariane 5: A $500M Lesson in Reuse Assumptions
The Ariane 5 Flight 501 failure  represents the gold standard of integration catastrophe. Forty seconds into what should have been a triumphant maiden flight, the rocket self-destructed, taking approximately $500 million in scientific satellites with it.
represents the gold standard of integration catastrophe. Forty seconds into what should have been a triumphant maiden flight, the rocket self-destructed, taking approximately $500 million in scientific satellites with it.
The root cause wasn’t a mysterious hardware failure. It was a software reuse decision that seemed perfectly reasonable in isolation. The Inertial Reference System software was carried over directly from the proven Ariane 4 platform. However, the Ariane 5’s superior performance characteristics generated horizontal velocity values that exceeded the Ariane 4 software’s data type limits, causing an integer overflow exception.
Here’s the integration failure: The overflow occurred in alignment code that was only relevant for the Ariane 4’s ground operations. It served no purpose during Ariane 5 flight. But because hardware and software teams operated in silos, this dead code path was never validated against the new system’s operational parameters. Both the primary and backup systems failed identically, eliminating redundancy.
Engineering Leadership Lesson: Software reuse without comprehensive re-verification in new hardware contexts is a systemic risk. Your integration testing must validate every code path against actual operational parameters, not just the “happy path” scenarios.
Boeing 737 MAX: When Automation Meets Integration Reality
The 737 MAX disasters illuminate how integration failures in safety-critical systems can have ultimate consequences. Boeing’s engineering challenge was elegant in its simplicity: larger, more efficient engines required different mounting positions, altering the aircraft’s pitch characteristics.
Boeing’s MCAS (Maneuvering Characteristics Augmentation System) was a software-driven flight control mechanism designed to automatically deploy nose-down trim when sensor inputs indicated an elevated angle of attack, helping to stabilize the aircraft under specific flight conditions. The fatal integration flaw was architectural: MCAS relied on input from a single, non-redundant sensor while having authority to override pilot control inputs.
When that sensor provided erroneous data, MCAS created an unstable feedback loop, repeatedly commanding nose-down deflection that pilots couldn’t understand or counteract. This wasn’t a software bug or hardware failure in isolation; it was a systems-level integration failure that didn’t account for fault modes in the human-machine interface.
Technical Leadership Insight: In safety-critical systems, your integration architecture must explicitly model and test failure modes across all system boundaries—hardware sensors, software logic, and human operators.
Samsung Galaxy Note 7: The $17 Billion Integration Crisis
 The Galaxy Note 7 was poised to be a market leader until reports surfaced of devices catching fire and exploding. The crisis culminated in two separate global recalls, permanent product discontinuation, and an estimated $17 billion in lost revenue and recall costs.
The Galaxy Note 7 was poised to be a market leader until reports surfaced of devices catching fire and exploding. The crisis culminated in two separate global recalls, permanent product discontinuation, and an estimated $17 billion in lost revenue and recall costs.
The immediate technical cause was hardware flaws in lithium-ion batteries from two different suppliers. Investigations identified manufacturing defects: batteries with outer pouches too small for internal components, causing electrode compression and separator damage, and welding defects creating sharp protrusions that could puncture insulating layers.
However, the crisis was born from socio-technical failure. Samsung was aggressively racing to launch before Apple’s iPhone 7, translating corporate pressure down to engineering teams. This rush led to compromised design and validation processes. The hardware design pushed battery technology limits with exceptionally thin separators to maximize capacity, leaving virtually no safety margin within the phone’s physical constraints.
Samsung’s response highlighted the complex hardware-software interplay: after the first recall failed, they issued mandatory software updates limiting battery charging capacity and eventually “bricked” remaining devices. This demonstrates how software becomes a costly, last-resort tool to mitigate hardware failures that should have been prevented during integrated design and verification.
Automotive: The Integration Tax in Real-Time
Modern automotive development provides a continuous case study in integration complexity management. Today’s vehicles contain over 100 million lines of code distributed across dozens of Electronic Control Units from multiple suppliers. The integration challenges are systemic and ongoing:
- Hardware-Software Version Misalignment: In a 2022 recall, Volkswagen and Audi vehicles experienced issues because the brake control unit hardware had been updated, but the corresponding software module was not adjusted to account for the change—resulting in incompatibility between the two components.
- Intermittent Interface Failures: Ford’s transmission downshift recall was caused by intermittent sensor signal loss to the Powertrain Control Module—a classic hardware-software boundary failure.
- Integration Mapping Errors: Tesla’s trailer brake light failure resulted from new hardware components that weren’t properly mapped in the vehicle control software.
These aren’t one-off bugs—they represent the ongoing cost of managing complex supplier ecosystems where individual components are developed independently and integrated late in the cycle.
The Strategic Imperative: Shifting from Reactive Integration to Proactive Co-Design
The pattern across these failures is clear: integration treated as a late-stage activity creates exponential risk. The strategic response requires abandoning traditional “over-the-wall” development models in favor of concurrent hardware-software co-design.
The Flaw of the Siloed Approach
The conventional “waterfall” or “over-the-wall” process forces software to conform to hardware platforms designed with incomplete understanding of software needs and complexities. This often leads to situations where software engineers devise convoluted solutions to problems that could have been easily solved with minor hardware design changes.
Matt Matl, VP of Software at Ambi Robotics, captures the practical reality perfectly: “Engineers have to patch a lot more holes and try to solve a lot of software problems that don’t belong. Maybe I’m trying to solve a difficult picking problem, but it would be a lot easier if my gripper were optimized for the things I’m picking”.
Embracing the Co-Design Philosophy
Co-design dismantles traditional barriers between hardware and software engineering teams, fostering collaborative environments where both disciplines work concurrently from project inception. It’s an iterative process characterized by “continual back-and-forth,” where early software prototyping insights can influence hardware architecture, and hardware constraint realities can inform more efficient software algorithms.
This isn’tabout fundamentally reconceptualizing your development organization. Co-design requires a shift in organizational structure, breaking down barriers between traditionally separate hardware and software teams.
Implementation Framework: Technologies and Methodologies for Technical Leaders
Development Methodology Selection
Waterfall: Appropriate for projects with stable requirements and regulatory constraints, but creates maximum integration risk by deferring all verification to the end of the cycle. Its emphasis on comprehensive upfront documentation can be beneficial for hardware development and highly regulated industries requiring meticulous traceability.
projects with stable requirements and regulatory constraints, but creates maximum integration risk by deferring all verification to the end of the cycle. Its emphasis on comprehensive upfront documentation can be beneficial for hardware development and highly regulated industries requiring meticulous traceability.
Pure Agile: Excellent for software-centric projects with its emphasis on flexibility, iterative development, and continuous stakeholder feedback, but struggles with hardware dependencies and long lead times for physical components.
Hybrid Approach: The optimal solution for most integrated systems offering structured hardware development phases with embedded Agile software sprints and planned integration synchronization points. This model uses structured, Waterfall-like frameworks for long-lead hardware development while allowing software teams to operate using Agile sprints within that framework.
Virtual Prototyping: Enabling Left-Shift Integration
Virtual prototypes provide binary-compatible software models of your hardware platform, enabling software development months before physical silicon availability. This technology directly addresses the critical path bottleneck where software teams wait for hardware availability.
A virtual prototype is a fully functional, high-speed software model of a hardware system that can execute the exact same, unmodified production code—from low-level firmware and drivers to operating systems and high-level applications—that will run on final physical silicon.
Key capabilities include:
- Early Software Development: Begin firmware and application development against a stable, functional model months before hardware design completion or first chips from fabrication.
- Continuous Integration: The virtual prototype serves as a stable, common reference for both hardware and software teams. As hardware engineers complete blocks of their design, these can be swapped into the virtual prototype for co-verification against the real software stack.
- Enhanced Debug Visibility: Virtual prototypes offer unparalleled visibility into system internal state. Engineers can pause the entire system, inspect every register and memory location state, and correlate software execution with hardware events in ways impossible with physical hardware, greatly accelerating complex hardware-software interaction bug diagnosis.
Model-Based Systems Engineering (MBSE): Creating Integration Truth
MBSE replaces document-based engineering with interconnected digital models that serve as the authoritative system definition. This creates a “digital thread” linking requirements through implementation to verification.
Core benefits for integration management:
- Enhanced Collaboration and Communication: Using standardized modeling languages like SysML (Systems Modeling Language), MBSE provides common, unambiguous language for all engineering disciplines to work from the same shared model, ensuring stakeholder alignment and reducing the risk of misinterpreting requirements or interface specifications.
- Improved Traceability: MBSE creates clear, digital links from high-level stakeholder requirements down to specific hardware and software components implementing them, and onward to test cases verifying them. This allows automated impact analysis, instantly showing how proposed changes to one system part will affect all other dependent parts.
- Early Simulation and Analysis: The system model isn’t just static diagrams; it can be executed and simulated. This allows engineers to validate system behavior, identify requirement conflicts, discover interface gaps, and analyze performance trade-offs long before any hardware is built or code is written, effectively de-risking projects at the earliest possible stage.
The Technical Leader’s Decision Framework
The choice is clear: get hardware-software integration right from the start or pay for the fallout later. When every product relies on that alignment, there’s no middle ground.
A late-stage integration failure triggers rework, which delays launch. That delay gives competitors a head start and costs you critical market share. In the scramble to recover, rushed fixes often introduce new issues or undercut product quality. Customers notice—and they talk. The result? A damaged reputation that drags down not just this launch, but the next one too. One integration miss can set off a chain reaction that stalls momentum for years.
The companies that solve this problem unlock faster time-to-market, more reliable products, and the bandwidth to focus on what’s next—not what went wrong. The rest will stay stuck in a loop of missed launches and mounting technical debt.
Because the real cost of integration isn’t what you spend upfront—it’s what you lose when you get it wrong.
Ready to Break the Cycle?
If your team is still discovering integration issues late in the game—or firefighting problems that should’ve been solved in design—we can help. At Geisel Software, we’ve partnered with teams in robotics, medical devices, and aerospace to architect integrated systems that ship on time and just work. Check out some of our projects here.
Let’s talk about how to make integration your advantage—not your bottleneck.




